 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA critical assessment of reinforcement learning methods for microswimmer navigation in complex flows
May 08, 2025Navigating in a fluid flow while being carried by it, using only information accessible from on-board sensors, is a problem commonly faced by small planktonic organisms. It is also directly relevant to autonomous robots deployed in the oceans. In the last ten years, the fluid mechanics community has widely adopted reinforcement learning, often in the form of its simplest implementations, to address this challenge. But it is unclear how good are the strategies learned by these algorithms. In this paper, we perform a quantitative assessment of reinforcement learning methods applied to navigation in partially observable flows. We first introduce a well-posed problem of directional navigation for which a quasi-optimal policy is known analytically. We then report on the poor performance and robustness of commonly used algorithms (Q-Learning, Advantage Actor Critic) in flows regularly encountered in the literature: Taylor-Green vortices, Arnold-Beltrami-Childress flow, and two-dimensional turbulence. We show that they are vastly surpassed by PPO (Proximal Policy Optimization), a more advanced algorithm that has established dominance across a wide range of benchmarks in the reinforcement learning community. In particular, our custom implementation of PPO matches the theoretical quasi-optimal performance in turbulent flow and does so in a robust manner. Reaching this result required the use of several additional techniques, such as vectorized environments and generalized advantage estimation, as well as hyperparameter optimization. This study demonstrates the importance of algorithm selection, implementation details, and fine-tuning for discovering truly smart autonomous navigation strategies in complex flows.
Visual collective behaviors on spherical robots
Sep 30, 2024The implementation of collective motion, traditionally, disregard the limited sensing capabilities of an individual, to instead assuming an omniscient perception of the environment. This study implements a visual flocking model in a ``robot-in-the-loop'' approach to reproduce these behaviors with a flock composed of 10 independent spherical robots. The model achieves robotic collective motion by only using panoramic visual information of each robot, such as retinal position, optical size and optic flow of the neighboring robots. We introduce a virtual anchor to confine the collective robotic movements so to avoid wall interactions. For the first time, a simple visual robot-in-the-loop approach succeed in reproducing several collective motion phases, in particular, swarming, and milling. Another milestone achieved with by this model is bridging the gap between simulation and physical experiments by demonstrating nearly identical behaviors in both environments with the same visual model. To conclude, we show that our minimal visual collective motion model is sufficient to recreate most collective behaviors on a robot-in-the-loop system that is scalable, behaves as numerical simulations predict and is easily comparable to traditional models.
How memory architecture affects performance and learning in simple POMDPs
Jun 16, 2021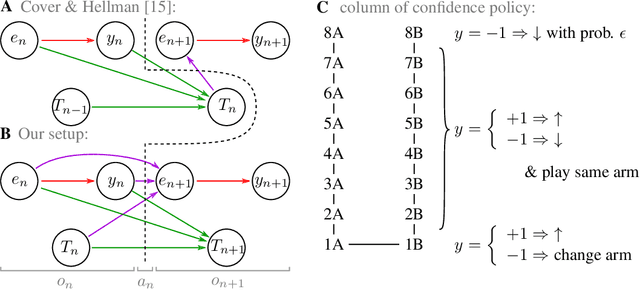
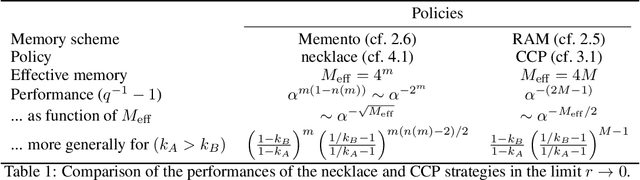
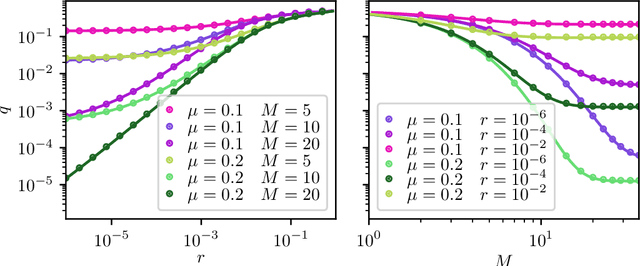

Reinforcement learning is made much more complex when the agent's observation is partial or noisy. This case corresponds to a partially observable Markov decision process (POMDP). One strategy to seek good performance in POMDPs is to endow the agent with a finite memory, whose update is governed by the policy. However, policy optimization is non-convex in that case and can lead to poor training performance for random initialization. The performance can be empirically improved by constraining the memory architecture, then sacrificing optimality to facilitate training. Here we study this trade-off in the two-arm bandit problem, and compare two extreme cases: (i) the random access memory where any transitions between $M$ memory states are allowed and (ii) a fixed memory where the agent can access its last $m$ actions and rewards. For (i), the probability $q$ to play the worst arm is known to be exponentially small in $M$ for the optimal policy. Our main result is to show that similar performance can be reached for (ii) as well, despite the simplicity of the memory architecture: using a conjecture on Gray-ordered binary necklaces, we find policies for which $q$ is exponentially small in $2^m$ i.e. $q\sim\alpha^{2^m}$ for some $\alpha < 1$. Interestingly, we observe empirically that training from random initialization leads to very poor results for (i), and significantly better results for (ii).